The implicit-bias program
Why does training a model without an explicit regularizer, with the loss driven nearly to zero, still produce a solution that generalizes? The classical answer is that the objective has to carry the regularizer somewhere. The implicit-bias answer is more subtle: even when the objective has many minima, gradient descent does not choose among them neutrally; the algorithm itself selects a particular kind of solution.
Zhang et al. [2] sharpened the puzzle that most of this literature now opens with. Standard image classifiers fit random labels as easily as they fit true ones, which kills the simplest capacity-based explanation of generalization: the hypothesis class is large enough to memorize anything. Whatever is producing the generalization, then, must come from the optimizer, the data, or the parameterization, not from the loss function itself.
The clearest version of this story is not actually about neural networks. It is about logistic regression on linearly separable data. Once the classifier separates the data, the empirical classification error is already 0% and the logistic loss continues to decrease as the norm of the weights grows. There is no finite minimizer. What is more surprising is that the direction of the weights still converges. And it converges to the maximum-margin SVM solution.
The linear theorem
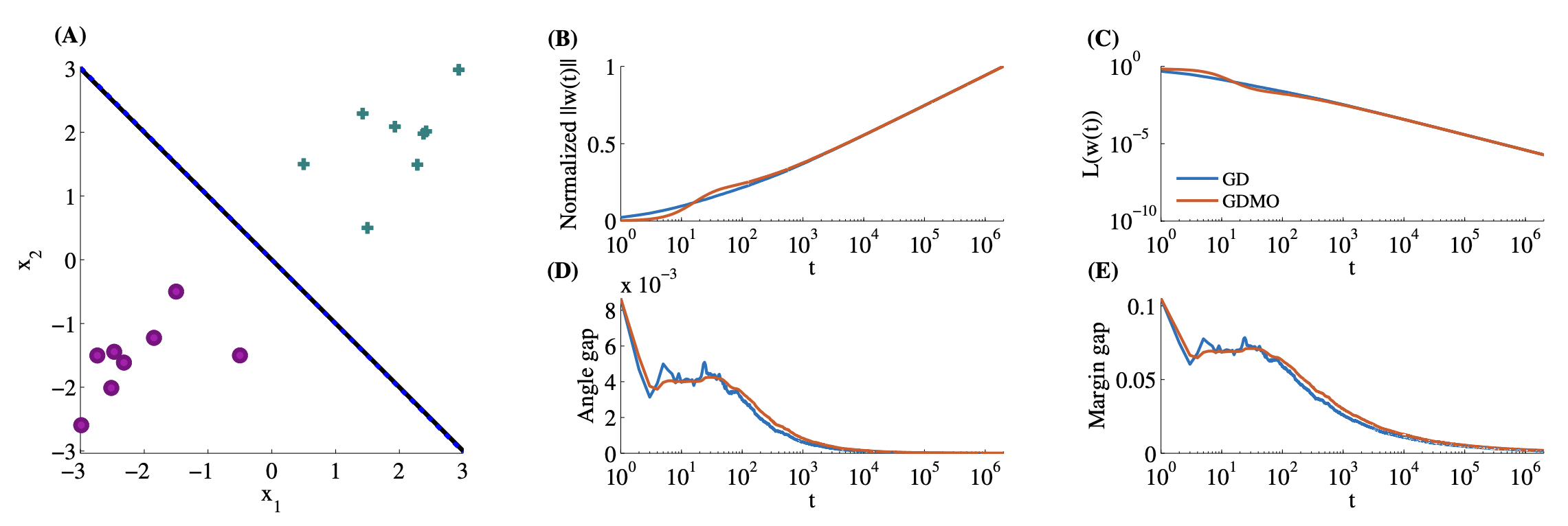
Let \(x_i \in \mathbb{R}^d\) denote an input vector with binary label \(y_i \in \{-1,+1\}\), and let \(w_t \in \mathbb{R}^d\) denote the weight vector at iteration \(t\). For linearly separable data \(\{(x_i, y_i)\}_{i=1}^{n}\), standard gradient descent on the logistic loss sends \(\lVert w_t \rVert \to \infty\), but the normalized direction \(w_t / \lVert w_t \rVert\) converges to the L2 max-margin direction \(\hat{w} / \lVert \hat{w} \rVert\), where \[\hat{w} \;=\; \arg\min_{w \in \mathbb{R}^d} \tfrac{1}{2}\lVert w\rVert^2 \quad \text{s.t.}\quad y_i\,w^{\top} x_i \ge 1 \quad \forall i \in [n].\]
In words: once the classifier has separated the data, gradient descent keeps reducing the logistic loss as long as the separation is preserved, except that unlike a traditional SVM it does so while continuing to grow the norm of the weights without bound. The norm grows only logarithmically with \(t\), and the angle gap between \(w_t/\lVert w_t\rVert\) and \(\hat w/\lVert\hat w\rVert\) closes at the same logarithmic rate. This is why the asymptotic regime takes so many iterations to become visible.
A few things follow from the theorem. Gradient descent behaves as if it had been regularized toward the Euclidean max-margin classifier without anyone writing that regularizer down. It also explains why early stopping helps: because the weight norm diverges over time, stopping early caps the implicit penalty before the iterate gets too far. Ji and Telgarsky extended the result to the non-separable case, showing the iterate still tracks a unique ray defined by the data when no separating hyperplane exists. Nacson et al. [4] showed that aggressive learning-rate schedules accelerate convergence to the max-margin direction by polynomial factors over plain GD. The norm divergence itself is robust to dataset size and dimension: as long as the data is linearly separable, the iterate keeps moving away from the origin and never lands at a finite minimum.
The geometry enters
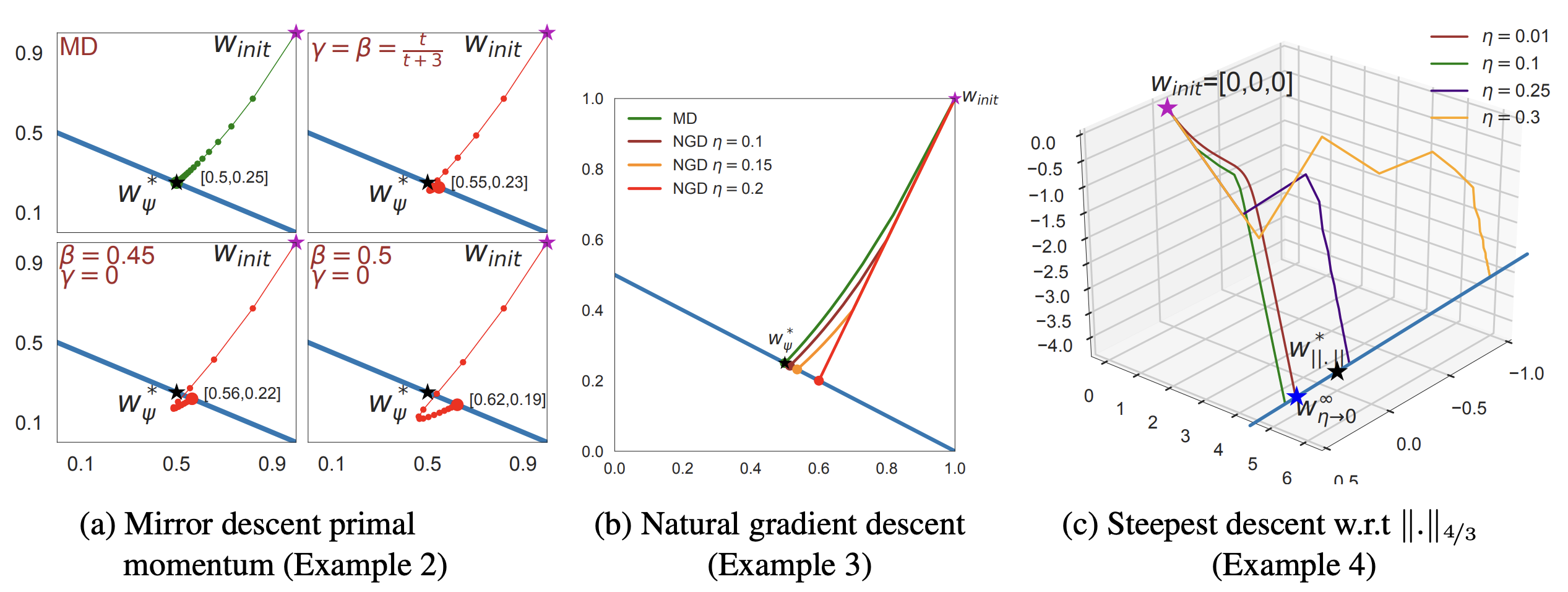
Gunasekar et al. [3] generalized the result: different optimization geometries select different implicit regularizers. Steepest descent under the \(\ell_p\) norm minimizes the \(\ell_p\) margin instead of the \(\ell_2\) margin. Mirror descent with respect to a convex potential \(\Phi\) minimizes the \(\Phi\)-min-norm interpolant. Natural gradient and adaptive methods land at interpolants determined by the geometry of their step.
The linear-convolutional-network result is the cautionary case. For fully connected linear predictors, gradient descent picks out the familiar $\ell_2$ margin geometry. For full-width linear convolutional networks of depth $L$, Gunasekar et al. show that gradient descent instead selects the predictor minimizing the $2/L$-bridge penalty in the discrete Fourier domain. The architecture changes which parameters are being optimized, and that change shifts both the trajectory and the preferred solution. "Gradient descent likes simple solutions" is too vague to be a theorem. The more honest statement is that gradient descent likes simple solutions in whichever coordinate system the architecture imposes.
Margin in homogeneous networks
Lyu and Li push the result past linear predictors. If \(f_\theta\) is positively homogeneous in \(\theta\) with order \(L\) (which holds for ReLU networks without bias, with \(L\) equal to depth), then gradient flow on exponential or logistic loss drives \(\theta_t / \lVert \theta_t \rVert\) to a KKT point of the parameter-space margin program \(\max_{\lVert \theta \rVert \leq 1}\, \min_i\, y_i f_\theta(x_i)\). The norm still diverges; the normalized direction still converges; the new content is that even on a non-convex parameter landscape, gradient flow lands on points satisfying first-order optimality conditions for the margin program.
Chizat and Bach prove a parallel mean-field result for two-layer networks with vanishing initializations. The implicit bias there is \(F_1\)-norm minimization in function space, which is a different object from parameter-space margin maximization and interacts differently with the data. The state of the field is that implicit regularization in deep networks has several reasonable descriptions, none of which generalize cleanly past shallow or homogeneous models.
It is widely thought that neural networks generalize because of implicit regularization of gradient descent. Today at #ICLR2023 we show new evidence to the contrary. We train with gradient-free optimizers and observe generalization competitive with SGD.https://t.co/8Vo9rFI9FY
— Tom Goldstein (@tomgoldsteincs) May 2, 2023
My own reading is that the implicit-bias program is one of the few cases I can point to of a research direction being vindicated and outgrown at the same time. Soudry et al. [1] is true; the mechanism is real; the linear case is the only setting where I can prove anything I trust. What is unclear is whether the same phenomenon is the dominant explanation for why large feature-learning networks generalize, or whether at scale the data distribution and the architecture have already done so much of the work that the optimizer's preference is a small correction. I currently believe the second, but I do not have a falsifier I trust, which is exactly the position the field is in.
Further reading
- S. Gunasekar, J. Lee, D. Soudry, and N. Srebro. Implicit bias of gradient descent on linear convolutional networks. arxiv 1806.00468, 2018
- Z. Ji and M. Telgarsky. Risk and parameter convergence of logistic regression. arxiv 1803.07300, 2018
- K. Lyu and J. Li. Gradient descent maximizes the margin of homogeneous neural networks. arxiv 1906.05890, 2019
- L. Chizat and F. Bach. Implicit bias of gradient descent for wide two-layer neural networks trained with the logistic loss. arxiv 2002.04486, 2020
- S. Pesme, L. Pillaud-Vivien, and N. Flammarion. Implicit bias of SGD for diagonal linear networks: a provable benefit of stochasticity. arxiv 2106.09524, 2021
- E. Moroshko, S. Gunasekar, B. Woodworth, J. D. Lee, N. Srebro, and D. Soudry. Implicit bias in deep linear classification: initialization scale vs training accuracy. arxiv 2007.06738, 2020
References
- [1] D. Soudry, E. Hoffer, M. S. Nacson, S. Gunasekar, and N. Srebro. The implicit bias of gradient descent on separable data. arxiv 1710.10345, 2017.
- [2] C. Zhang, S. Bengio, M. Hardt, B. Recht, and O. Vinyals. Understanding deep learning requires rethinking generalization. arxiv 1611.03530, 2016.
- [3] S. Gunasekar, J. Lee, D. Soudry, and N. Srebro. Characterizing implicit bias in terms of optimization geometry. arxiv 1802.08246, 2018.
- [4] M. S. Nacson, J. Lee, S. Gunasekar, P. H. P. Savarese, N. Srebro, and D. Soudry. Convergence of gradient descent on separable data. arxiv 1803.01905, 2019.