The neural tangent kernel
The neural tangent kernel was one of the few deep-learning theory ideas that were useful before they became a concept. It doesn't solve generalization, but it makes a very stubborn object analyzable. Jacot, Gabriel, and Hongler [1] found that if you take a network to infinite width under the right scaling, gradient descent on the parameters becomes kernel gradient descent in function space. The kernel isn't chosen by hand, it's induced by the network at initialization. For a model $f_\theta$, the tangent kernel is $K_\theta(x, x') = \nabla_\theta f_\theta(x)^\top \nabla_\theta f_\theta(x')$. In finite networks this kernel changes as you train. In the infinite width limit under the standard parameterization, it converges to some deterministic kernel $K_\infty$ and $\|K_{\theta_t} - K_\infty\|$ approaches $O(1/\sqrt{n})$ in width $n$.
Function-space gradient descent then satisfies $\dot{f}_t = -K_\infty (f_t - y)$ on the training set and integrates to $f_t = y + e^{-K_\infty t}(f_0 - y)$. Parameter-space non-convexity stops mattering: the function-space dynamics are linear and driven by a positive semidefinite kernel.
NTK as baseline
The first thing the NTK explained is why very wide networks optimize so easily. If the kernel is well conditioned on the training data, gradient descent has an easy road to interpolation. The complicated nonconvex path is, at leading order, kernel regression with some specific architecture induced kernel. Du et al. [4] and Lee et al. [2] pushed this picture further and showed that wide networks of any depth evolve like their first-order Taylor expansion around initialization.
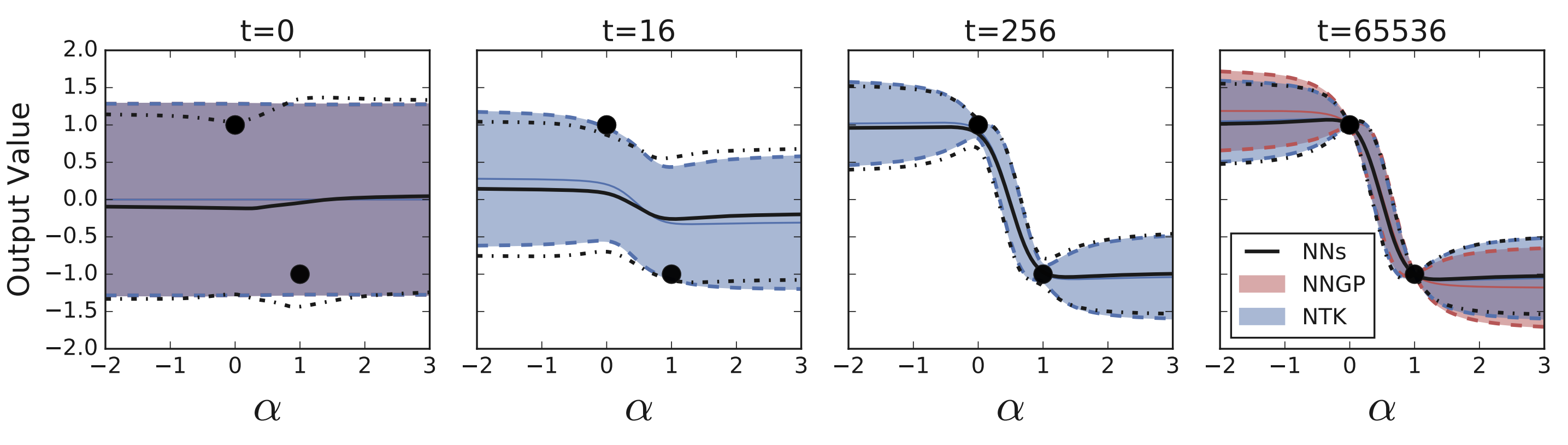
Du et al. extend the same machinery to a clean proof that overparameterized networks reach zero training loss with a polynomial-width requirement and a global-convergence guarantee that the nonconvex landscape never gave you. But the spectrum of $K_\infty$ does more than set the speed of convergence. Its eigendecomposition $K_\infty = \sum_k \lambda_k \phi_k \phi_k^\top$ implies that the residual along eigenmode $\phi_k$ shrinks like $e^{-\lambda_k t}$, so large-eigenvalue modes are learned quickly and small-eigenvalue modes slowly, or not at all under early stopping. Early stopping, the frequency principle, and the spectral bias of MLPs all become statements about $\{\lambda_k\}$.
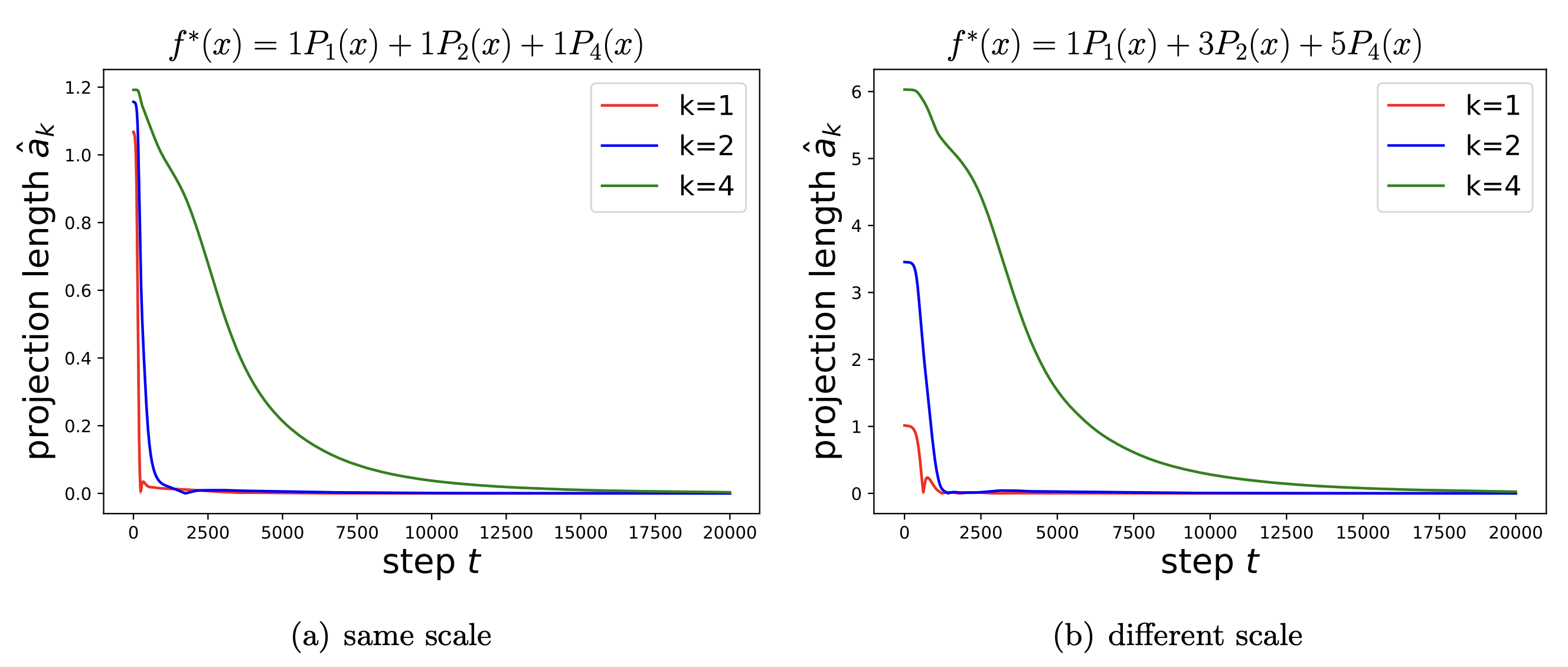
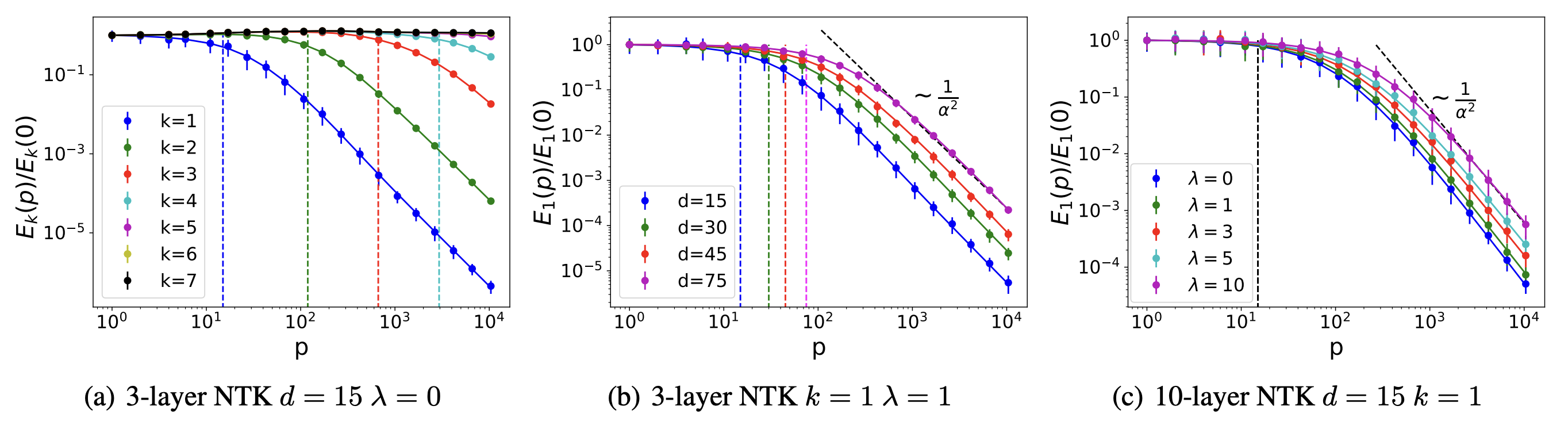
Arora et al. write down an exact algorithm for computing $K_\infty$ for fully connected and convolutional networks of arbitrary depth, making these spectral predictions empirically testable on real datasets.
The lazy-training caveat
The catch is that the same condition that makes the theory clean also removes one of the main things deep networks seem to be doing. In the NTK limit, features do not move. Parameters drift by $\|\theta_t - \theta_0\| = O(1/\sqrt{n})$ in width $n$ while the function changes by $O(1)$, so the network is producing its outputs by reweighting an almost fixed collection of random features. Chizat, Oyallon, and Bach call this the lazy-training regime and emphasize that it is a property of the scaling, not a universal description of neural networks.
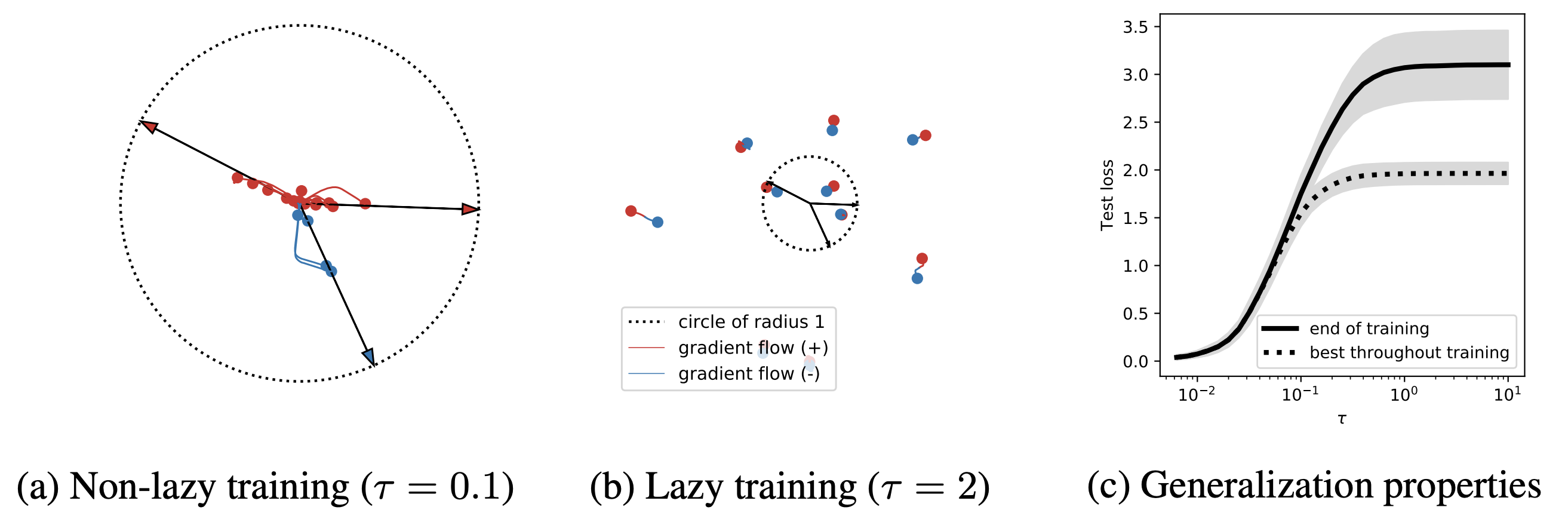
That caveat matters; a convolutional network trained in the lazy regime can optimize while failing to learn the representations that make convolutional networks useful. A transformer that looks like a fixed random-feature model is not the object that in-context learning, induction-head formation, and abstraction discussions are pointing at. The NTK gives a rigorous theory of one limit. The question is whether that limit keeps the right phenomena. Geiger et al [5] report a sharp empirical separation: at moderate width and standard initialization scale networks operate near the lazy regime; at lower initialization scale (or if explicit feature-learning parameterizations are used) the same architecture enters a regime where features evolve and test error improves.
The transition is controlled by initialization scale and width, not by anything intrinsic to the architecture. That is a slightly disappointing answer if you wanted neural networks to be feature learners by default.
The NTK is not wrong; it is a baseline. A phenomenon that already appears in the NTK limit can be attributed to width, interpolation, and fixed random features, with no representation learning needed. A phenomenon that disappears in the NTK limit is the work of feature learning, finite-width fluctuation, architecture-specific structure, or nonlinearity in the optimization. That makes the NTK a useful negative control for theoretical claims about deep learning, and the simpler question to put to such a claim is: would it still hold if the features were frozen? For most optimization claims, yes. For most generalization and capability claims, no. The Distill circuits thread is the non-theorem-shaped version of what feature learning looks like when someone manages to pry a model open. Greg Yang's $\mu$P writeup is the practical entry into Tensor Programs, and the microsoft/mup repo is what to grab when the goal is hyperparameter transfer and not the theory.
Excited to share our new #neurips2020 paper /Deep learning versus kernel learning: an empirical study of loss landscape geometry and the time evolution of the Neural Tangent Kernel/ (https://t.co/4jmrNfOE6H) with @KDziugaite, Mansheej, @SKharaghani, @roydanroy, @SuryaGanguli 1/6 pic.twitter.com/iPPP3HmNgm
— Stanislav Fort (@stanislavfort) October 30, 2020
Feature learning is the missing term
The frontier after the NTK was to build infinite-width limits in which features actually move. Mean-field limits treat each unit as a particle in a measure and study gradient flow on that measure; in this scaling features evolve and the kernel is no longer constant. Tensor-program analyses catalogue the parameterizations that produce sensible infinite-width limits at all. The maximal-update parameterization $\mu$P, introduced by Yang and Hu in Tensor Programs IV (arxiv 2011.14522), is the one that keeps both feature learning and stable optimization in the limit. The follow-up Tensor Programs V (arxiv 2203.03466) derives the $\mu$Transfer hyperparameter-transfer rules from that analysis: tune at small width, scale to large width, and the learning-rate schedule transfers without retuning.
Feature learning means the tangent kernel is moving substantively: $K_{\theta_t} - K_{\theta_0}$ is a structured rotation of the features toward the data, not a small perturbation. The parameter-gradients at the end of training are not the same object as at initialization, and the network has in effect changed the basis it works in. That change is exactly what the pure NTK limit suppresses. Fort et al. ran one of the clearest empirical comparisons: kernel learning matches a finite network early in training but the two diverge later, and the divergence is the gap between lazy convergence to a fixed kernel and feature-driven re-shaping of it.
I use the NTK as a falsifier, not a model. If a proposed mechanism for a deep-learning phenomenon is already trivially in the NTK regime, then "the network is wide and the features are random" suffices, and the explanation has not earned the depth of its hypothesis. The interesting predictions are the ones that disagree with the kernel: where width, lazy init, and architecture-induced spectra are not enough, and where representation change must be doing the work. That includes in-context learning, induction-head formation, and the parts of scaling laws that depend on where compute is spent.
Further reading
- S. Arora, S. S. Du, W. Hu, Z. Li, R. Salakhutdinov, and R. Wang. On exact computation with an infinitely wide neural net. arxiv 1904.11955, 2019
- M. Belkin, D. Hsu, S. Ma, and S. Mandal. Reconciling modern machine learning practice and the bias-variance trade-off. arxiv 1812.11118, 2018
- S. Mei, A. Montanari, and P.-M. Nguyen. A mean field view of the landscape of two-layer neural networks. arxiv 1804.06561, 2018
- G. Yang and E. J. Hu. Tensor Programs IV: feature learning in infinite-width neural networks. arxiv 2011.14522, 2020
- Y. Cao, Z. Fang, Y. Wu, D.-X. Zhou, and Q. Gu. Towards understanding the spectral bias of deep learning. arxiv 1912.01198, 2019
- B. Bordelon, A. Canatar, and C. Pehlevan. Spectrum dependent learning curves in kernel regression and wide neural networks. arxiv 2002.02561, 2020
References
- [1] A. Jacot, F. Gabriel, and C. Hongler. Neural tangent kernel: convergence and generalization in neural networks. arxiv 1806.07572, 2018.
- [2] J. Lee, L. Xiao, S. S. Schoenholz, Y. Bahri, R. Novak, J. Sohl-Dickstein, and J. Pennington. Wide neural networks of any depth evolve as linear models under gradient descent. arxiv 1902.06720, 2019.
- [3] L. Chizat, E. Oyallon, and F. Bach. On lazy training in differentiable programming. arxiv 1812.07956, 2018.
- [4] S. S. Du, X. Zhai, B. Póczos, and A. Singh. Gradient descent provably optimizes over-parameterized neural networks. arxiv 1810.02054, 2018.
- [5] M. Geiger, S. Spigler, A. Jacot, and M. Wyart. Disentangling feature and lazy training in deep neural networks. arxiv 1906.08034, 2019.
- [6] S. Fort, G. K. Dziugaite, M. Paul, S. Kharaghani, D. M. Roy, and S. Ganguli. Deep learning versus kernel learning: an empirical study of loss landscape geometry and the time evolution of the neural tangent kernel. arxiv 2010.15110, 2020.