Double descent, the U that became a W and what survived at scale
The durable contribution is not the W-shaped curve. It is the argument that classical capacity measures do not predict generalization in the regime where deep learning operates.
Key terms used in this post
- interpolation threshold
- the capacity at which training error first hits zero; historically the right edge of the classical U.
- label noise
- deliberately corrupted training labels; amplifies the double descent peak and is required for its sharpest form.
- implicit regularization
- the unproven and useful thesis that SGD selects a specific well-generalizing solution from the space of interpolants.
The bias-variance curve in every introductory machine learning textbook is a U. Error first drops as we increase model capacity, then climbs back up as the model starts to overfit. Everything in classical statistical learning theory is built on top of this shape, from Vapnik-Chervonenkis bounds to cross-validation protocols, and for decades it matched practice closely enough that nobody had a reason to look past it.
Modern deep networks do not live on this curve. The result that finally made the disagreement undeniable is Belkin et al. [1], which proposed and then demonstrated that once we push past the interpolation threshold, where the model has exactly enough capacity to fit the training set, test error starts to fall again. The classical U becomes a W with a second descent in the overparameterized regime, and the second descent often goes below the first minimum.
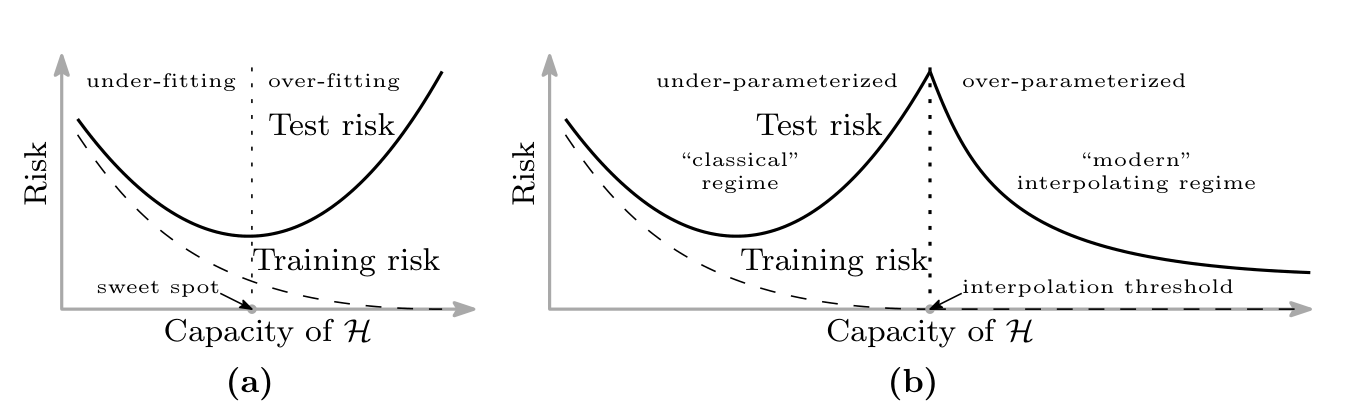
What Nakkiran actually showed
Nakkiran et al. [2] made the phenomenon concrete in a way Belkin’s paper had not, by showing that double descent appears not just in model size but also in training time and in dataset size. Model-wise double descent varies the width of a ResNet; epoch-wise varies the number of training steps; sample-wise varies the size of the training set with other hyperparameters fixed. The shape of the curve is the same in all three cases. A peak of test error around the interpolation threshold, then a descent as we push past it.
Epoch-wise is the most surprising of the three. It says that test error can get worse before it gets better during a single training run. If we stop training at the wrong moment, and that moment happens to be near where the training loss is close to zero but not quite, we see the worst model we will ever see. A little more training, and we are past the peak.
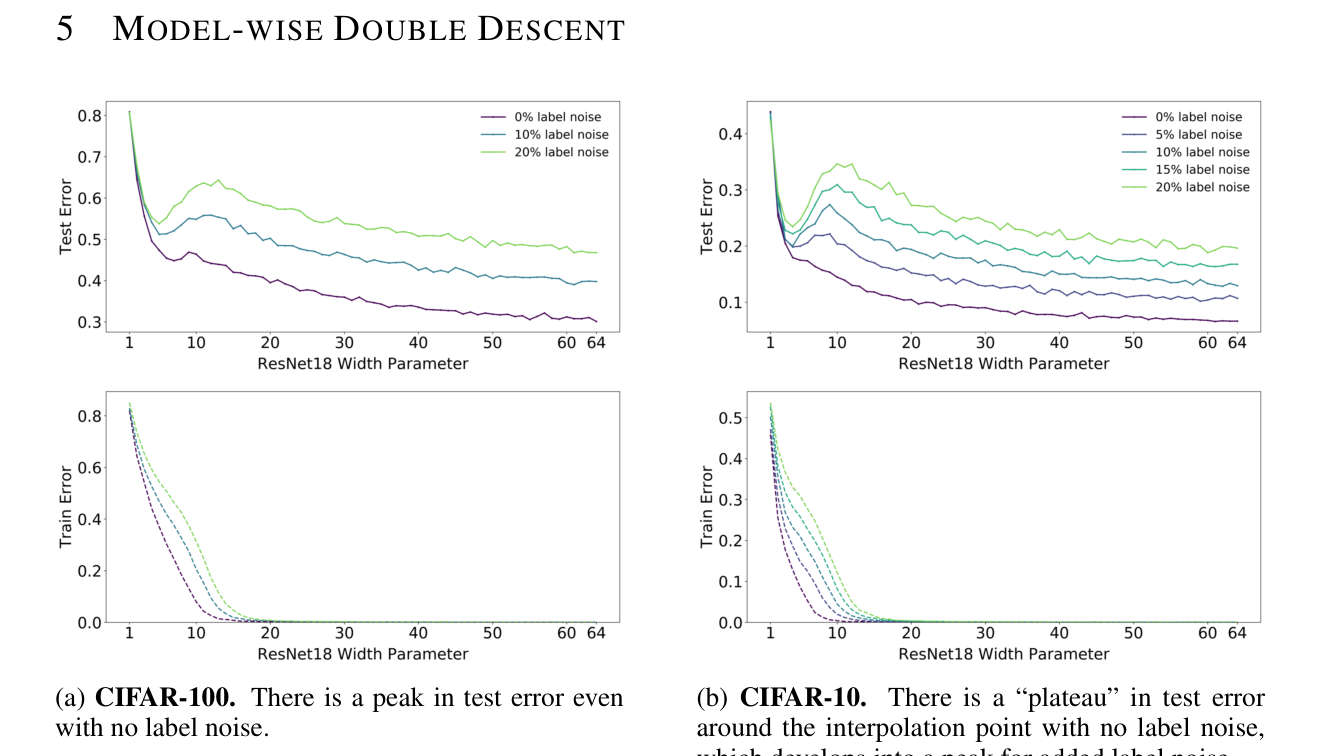
The label-noise caveat
The sharpest versions of the double descent peak in these papers come with label noise. Nakkiran’s headline plots use ten to twenty percent corrupted labels; without label noise, the peak is much weaker and sometimes absent. Label noise inflates the variance contribution of the model at the interpolation threshold, because the model is being asked to memorize random labels at exactly the capacity where memorization is possible but not easy. A little more capacity and the model can absorb the noise into higher-frequency components without disturbing the true signal.
This caveat matters because it is how the phenomenon connects to the rest of deep learning. The behavior in Belkin’s linear regression analysis survives at all noise levels but weakly; Nakkiran’s dramatic double descent curves require label noise; and at the scale of modern language model training, with clean labels and very large models, test loss is close to monotone in parameters. Scaling law papers report clean power-law decay on language modeling with no second peak visible. This does not refute double descent, but it does reshape the argument. The phenomenon is real and the bias-variance picture is genuinely wrong in the overparameterized regime, but the dramatic peak that gave the phenomenon its name is the label-noise case, not the generic case.
The reframing here was taken up at length by Boaz Barak on his blog Windows on Theory, where he argues that the interesting content of the double descent story is the shape to the right of the peak rather than the peak itself. The Nakkiran result was popularized further through OpenAI’s Deep Double Descent writeup, which drew a straight line from the empirical curves to the question of what kind of complexity control actually predicts generalization. My own take is closer to Barak’s position than to the version that made it into most practitioner slide decks.
What survives
The durable contribution of this line of work is not the W-shaped curve. It is the argument that classical capacity measures do not predict generalization in the regime where deep learning operates. The VC dimension of an overparameterized neural network is astronomical; by any pre-2015 theorem the test error in the overparameterized regime should be catastrophic, and instead it is often lower than anything achievable at smaller scale. Something about the implicit bias of the optimizer, or the geometry of the loss landscape, or both, selects a well-generalizing solution from a space where almost every interpolant is a terrible generalizer. Double descent forced people to take that argument seriously.
What also survives is the practical rule that in the overparameterized regime, bigger is almost always better if we can afford it. The second descent keeps going. This is why Kaplan [3] and the scaling law literature that followed found clean power-law decay as a function of compute: they were operating entirely on the right branch of the W, where the curve is smooth. The peak that everyone was debating in 2019 lives at a specific ratio of model size to data size that almost nobody targets on purpose.
What does not survive
The double descent result was sometimes read as implying that the bias-variance tradeoff is simply wrong, or that overfitting does not exist. Neither conclusion follows. Overfitting absolutely exists; we can see it in any small-data setting where the model is allowed to memorize. The correct reading is narrower. Above the interpolation threshold, in the presence of implicit regularization, larger models generalize better, not worse. This is a statement about a specific regime, not a universal one, and the counterexamples are easy to construct if we look outside that regime.
The other thing that does not cleanly survive is the story that the peak is always at the interpolation threshold. In practice, the location of the peak depends on the effective parameter count under the network’s implicit regularization, not the raw parameter count. This is why the peak in Nakkiran’s ResNet experiments does not sit exactly at the width where training error first hits zero. It sits slightly past it, at the width where the network can memorize the noisy labels without disturbing the signal. That is a finer statement and it is the one I think actually matches the evidence.
References
- [1] M. Belkin, D. Hsu, S. Ma, and S. Mandal. Reconciling modern machine learning practice and the bias-variance trade-off. arxiv 1812.11118, 2018.
- [2] P. Nakkiran, G. Kaplun, Y. Bansal, T. Yang, B. Barak, and I. Sutskever. Deep double descent: Where bigger models and more data hurt. arxiv 1912.02292, 2019.
- [3] J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei. Scaling laws for neural language models. arxiv 2001.08361, 2020.
- [4] T. Hastie, A. Montanari, S. Rosset, and R. J. Tibshirani. Surprises in high-dimensional ridgeless least squares interpolation. arxiv 1903.08560, 2019.
- [5] S. d’Ascoli, M. Refinetti, G. Biroli, and F. Krzakala. Double trouble in double descent: Bias and variance(s) in the lazy regime. arxiv 2003.01054, 2020.
- [6] P. Nakkiran, P. Venkat, S. Kakade, and T. Ma. Optimal regularization can mitigate double descent. arxiv 2002.11328, 2020.
- [7] G. Yang, E. J. Hu, I. Babuschkin, S. Sidor, D. Farhi, J. Pachocki, X. Liu, W. Ryan, and J. Gao. Tensor programs V: Tuning large neural networks via zero-shot hyperparameter transfer. arxiv 2203.03466, 2022.