The edge of stability and what it does to the flat-minima story
The classical descent lemma is not wrong for neural networks. It is, stranger than that, irrelevant.
Key terms used in this post
- descent lemma
- the classical convex-optimization bound saying gradient descent converges for step size below $2/\lambda_{\max}$.
- progressive sharpening
- the empirical observation that Hessian sharpness grows during training until it hits $2/\eta$.
- catapult phase
- a large-learning-rate transient where the loss briefly spikes before settling into a better basin, described by Lewkowycz et al.
Classical convex optimization theory gives a precise bound on the learning rate $\eta$ for gradient descent to converge. If the maximum eigenvalue of the Hessian at the current point is $\lambda_{\max}$, the step $\theta_{t+1} = \theta_t - \eta \nabla L$ is guaranteed to decrease the loss whenever $\eta < 2 / \lambda_{\max}$, and is guaranteed to diverge in some direction whenever $\eta > 2 / \lambda_{\max}$. This is called the descent lemma, or the stability threshold, and every first textbook on convex optimization establishes it in the first chapter. It is not wrong for neural networks. It is, stranger than that, irrelevant.
Cohen et al. [1] observed that in practice, gradient descent on neural networks trains in a regime where $\lambda_{\max}$ is above $2 / \eta$ most of the time. The step is formally unstable. Loss does not diverge. Instead the trajectory oscillates around a region of the loss landscape while making progress in the orthogonal directions. They named this regime the edge of stability, and the observation was that it is not an edge case but the ordinary regime of neural network training.
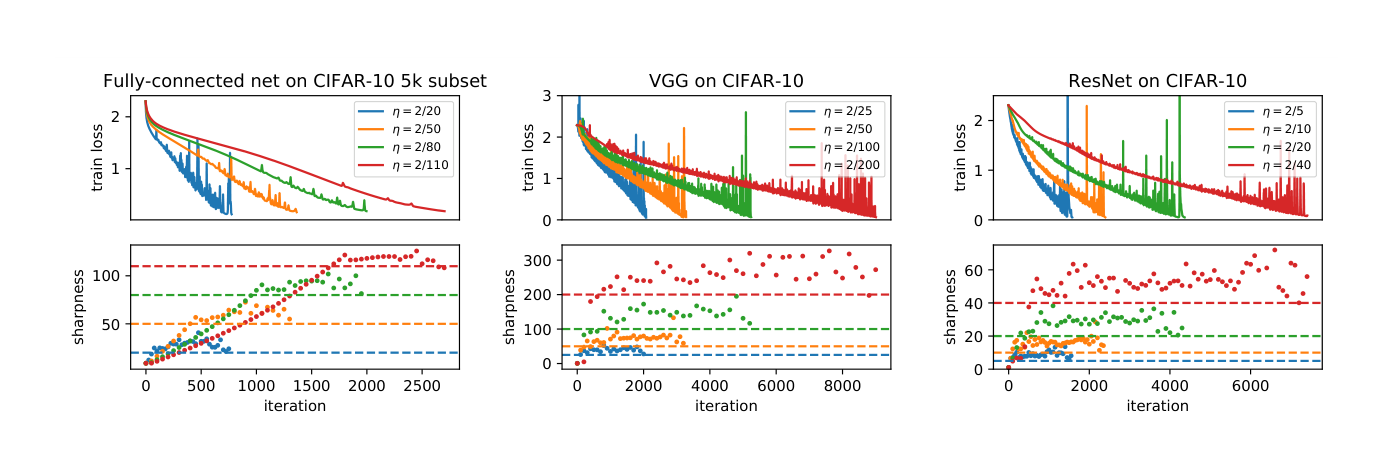
Progressive sharpening
The first phase Cohen identified is progressive sharpening. From a random initialization, gradient descent reliably drives the sharpness of the loss landscape upward during training. This is not trivial. Classical optimization intuition would say that the trajectory should steer away from sharp directions, because sharpness is the cost of a step. Neural network training does the opposite. It heads into sharp directions until it can no longer take a stable step.
Progressive sharpening itself is not well understood from first principles. Damian et al. [2] offered a self-stabilization argument that explains the phase once the threshold is reached, and Ahn et al. [4] extended this into a more complete picture, but neither derivation predicts progressive sharpening from initialization. The observational story is clear. The theoretical one is partial.
What happens at the threshold
Once sharpness reaches $2/\eta$, the classical theory says we should diverge. The observed behavior is that the trajectory starts oscillating along the eigendirection of $\lambda_{\max}$. The component of $\theta$ along that direction swings back and forth, but the loss keeps decreasing because progress in the other directions, which are well-conditioned, continues. The net effect is a trajectory that makes steady progress on loss while bouncing through a region of the landscape that classical theory predicts as unreachable.
Arora et al. [3] gave the first theoretical account of why this is not pathological. Their analysis works on a smoothed version of the loss, where the Hessian is held fixed and the argument tracks the trajectory of $\theta$. The result is that the oscillations across the unstable direction average out over a few steps. What we actually track is a slower dynamics that behaves like gradient descent on an effective loss where the sharp direction is clipped. This is formal enough that we can check which neural network training settings it applies to, and the answer is most of them.
What this means for flat minima
The older flat-minima narrative, going back to Hochreiter and Schmidhuber and reinforced by Keskar and the sharpness-aware-minimization literature, argued roughly as follows. SGD with small batches has noise in its gradients. The noise acts like a random walk that is more likely to escape sharp minima than flat ones. Therefore SGD has an inductive bias toward flat minima, and this bias is why neural networks generalize. The edge of stability result does not directly refute this story but it changes its shape significantly.
Under edge of stability, the learning rate itself imposes a sharpness ceiling. Any minimum with $\lambda_{\max} > 2 / \eta$ is not a stable attractor of gradient descent; the trajectory cannot sit there. SGD does not find flat minima because its noise escapes sharp ones. Gradient descent alone, without noise, would still end up in flat minima because it cannot stay in sharp ones at its learning rate. The batch noise story was explaining a real phenomenon using the wrong mechanism.
The clearest articulations of the theoretical reframing here come from two blogs. Sanjeev Arora’s Off-Convex has several posts on implicit bias, trajectory analyses, and why the classical descent lemma is genuinely misleading for neural networks rather than just approximately wrong. Ben Recht’s argmin is the complementary perspective on optimizer dynamics that depart from convex theory; his take is a little more skeptical and explicitly anti-hype, which is useful when the literature around a phenomenon gets crowded.
What this explains
A handful of phenomena start making sense under the edge-of-stability framing that were mysterious under the classical theory. Warmup, where we start training at a very small learning rate and increase it over a few thousand steps, works because it gives the network time to enter the edge-of-stability regime gradually, without the initial transient at high sharpness causing divergence. Learning rate schedules that decay $\eta$ over training work because reducing $\eta$ raises the sharpness ceiling that the trajectory is allowed to visit, which in turn lets the optimizer find a slightly sharper and typically better minimum in the final phase. Both of these were practiced empirically for years before a principled reason appeared.
The catapult mechanism of Lewkowycz et al. [5], where an initial spike in loss sometimes precedes a better final solution, is an instance of the same dynamics at a larger scale. A large learning rate pushes the trajectory into a region of the landscape where the Hessian is briefly very sharp, the loss spikes, and then the trajectory settles into a different basin than it would have reached with a smaller step.
What this does not explain
Edge of stability is a statement about trajectory dynamics, not a statement about generalization. It explains why SGD parks in flat minima. It does not explain why flat minima generalize. Those are separate questions, and the flat-minima generalization story has its own issues, which Dinh et al. [6] punctured by showing that sharpness is not reparameterization-invariant and so cannot be the thing that controls generalization at all.
The honest picture now is that edge of stability explains the shape of the trajectory, mode connectivity [7] explains the structure of the landscape of minima, and something we still do not have, probably related to the geometry of the data manifold interacting with the network’s Lipschitz constants along directions that matter, explains why one of those minima generalizes to the test set. The edge of stability literature is a significant step on the first question without claiming to touch the third.
References
- [1] J. M. Cohen, S. Kaur, Y. Li, J. Z. Kolter, and A. Talwalkar. Gradient descent on neural networks typically occurs at the edge of stability. arxiv 2103.00065, 2021.
- [2] A. Damian, E. Nichani, and J. D. Lee. Self-stabilization: The implicit bias of gradient descent at the edge of stability. arxiv 2209.15594, 2022.
- [3] S. Arora, Z. Li, and A. Panigrahi. Understanding gradient descent on edge of stability in deep learning. arxiv 2205.09745, 2022.
- [4] K. Ahn, J. Zhang, and S. Sra. Understanding the unstable convergence of gradient descent. arxiv 2212.07469, 2022.
- [5] A. Lewkowycz, Y. Bahri, E. Dyer, J. Sohl-Dickstein, and G. Gur-Ari. The large learning rate phase of deep learning: The catapult mechanism. arxiv 2003.02218, 2020.
- [6] L. Dinh, R. Pascanu, S. Bengio, and Y. Bengio. Sharp minima can generalize for deep nets. arxiv 1703.04933, 2017.
- [7] J. Frankle, G. K. Dziugaite, D. M. Roy, and M. Carbin. Linear mode connectivity and the lottery ticket hypothesis. arxiv 1912.05671, 2019.