On flat minima and the argument that won’t die
For about seven years now, the machine learning community has been arguing about whether flat minima generalize better than sharp minima. The argument keeps ending, and then a year later it keeps restarting. I want to lay out the state of it, because someone walking into the field today would reasonably conclude from a single textbook chapter that the question had been settled one way or the other. It has not.
Hochreiter, Schmidhuber, and the original intuition
Hochreiter and Schmidhuber [1] proposed that a solution in a wide basin of the loss landscape should generalize better than a solution in a narrow one. The intuition is information-theoretic: a wider minimum encodes less information about the training set, so it should be closer to the true underlying function. This was a good intuition and it sat there for almost two decades without generating much heat.
The modern revival came with Keskar et al. [2]. The argument was that large-batch SGD finds sharper minima than small-batch SGD, which explains why large batches generalize worse. The canonical one-dimensional sketch below launched a thousand follow-up papers.
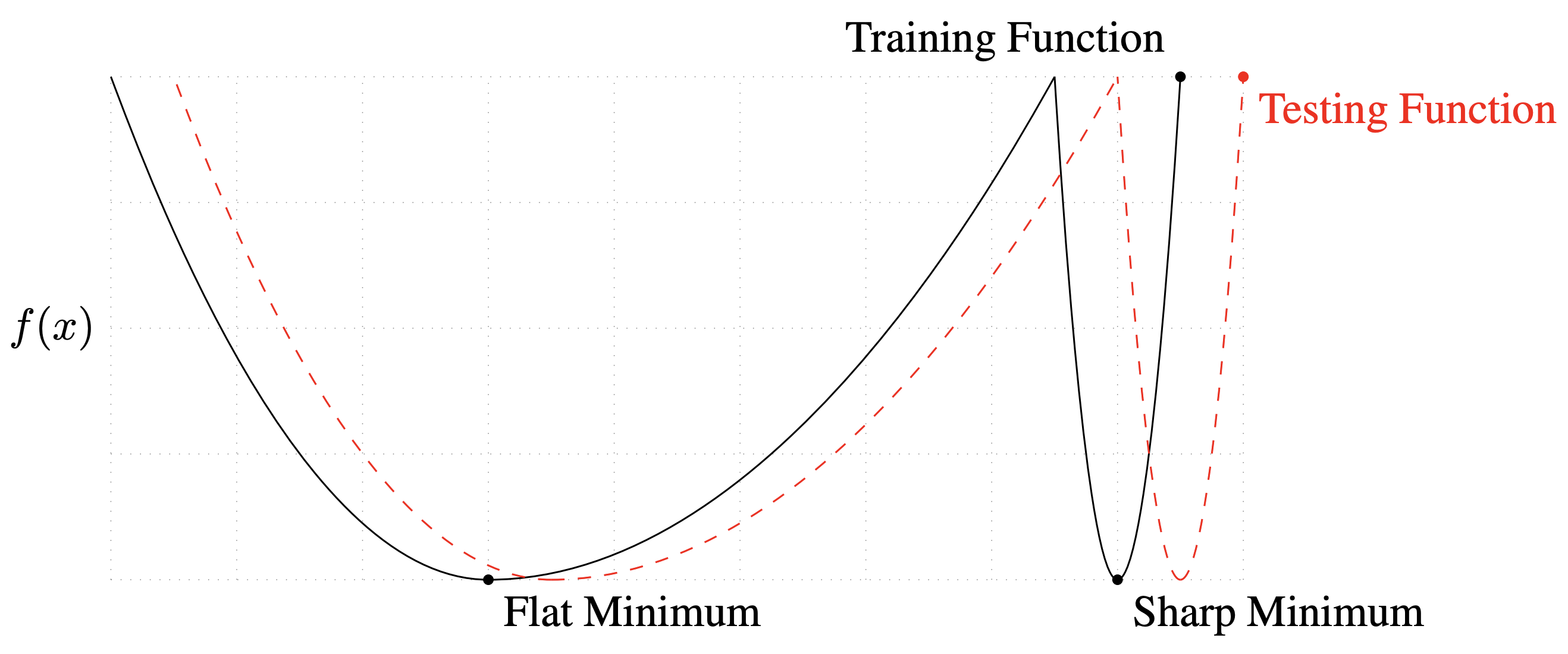
Dinh’s objection, which should have ended the conversation
It did not end the conversation, but it should have. Dinh et al. [3] pointed out that “sharpness” as measured by the Hessian is not a property of the function the network computes. It is a property of the parameterization. Given any minimum, you can reparameterize the weights so that the Hessian has arbitrarily large or small eigenvalues without changing the input-output map of the network at all. Whatever generalizes, it is not sharpness as naively defined.
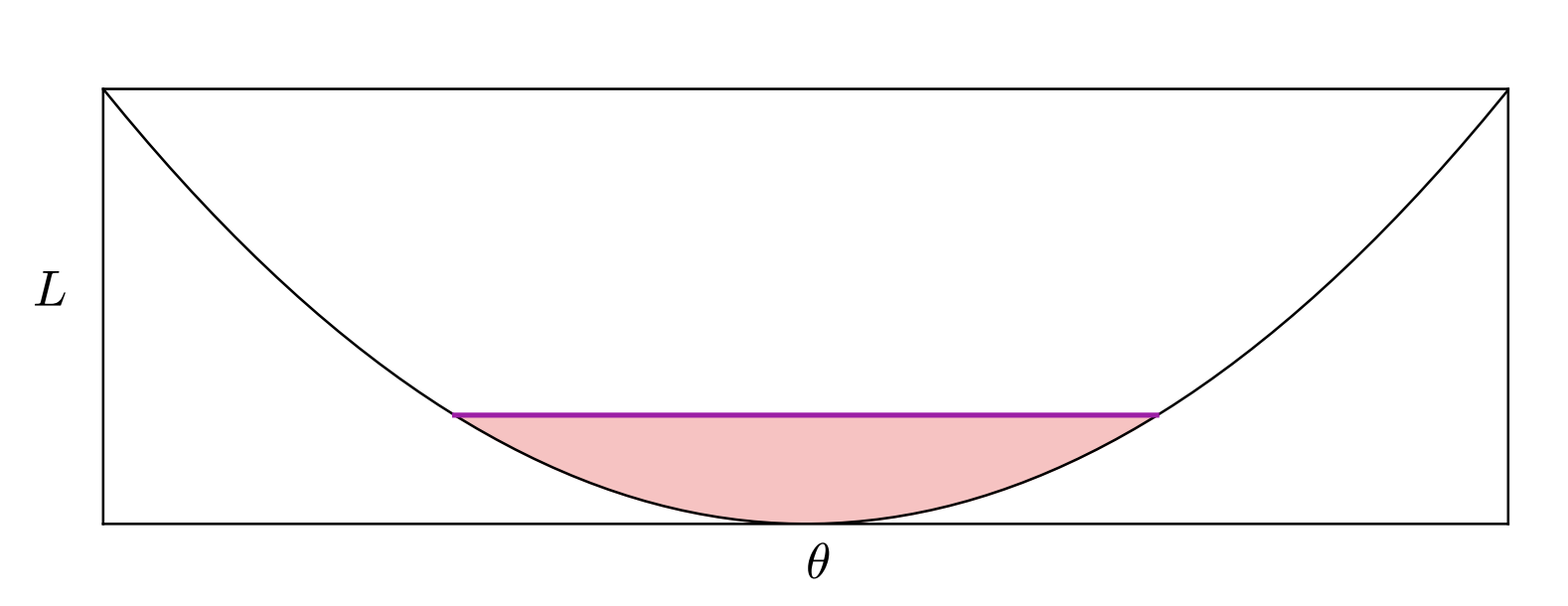
The honest response to this paper would have been to retire the flat-minima story; the actual response was to patch it. Several groups proposed sharpness measures that are invariant under reparameterization, on the grounds that the Hessian-based definition was the problem, not the underlying picture. Among these, the cleanest is the PAC-Bayes flavored definition of Dziugaite and Roy [4], which replaces the Hessian with the amount of weight noise you can tolerate while keeping the training loss low. That notion is reparameterization-invariant and does correlate with generalization in their experiments.
SAM and the regime where flatness wins
Foret et al. [5] took the next step and proposed to directly optimize for a reparameterization-aware sharpness during training. They called it Sharpness-Aware Minimization. SAM worked, sometimes dramatically. In particular it helped most on architectures with weak built-in inductive bias, where the training procedure rather than the architecture has to do the heavy lifting of generalization. Behnam Neyshabur, one of the authors, summarized the pattern in a thread the year after the paper came out.
Excited about trying Vision Transformer, Mixer or other new models on your data?
— Behnam Neyshabur (@bneyshabur) June 10, 2021
Don't forget to train with SAM instead of SGD/ADAM or might regret your decision!
By switching to SAM:
ViT and Mixer improve 5% & 11% on ImageNet
ViT and Mixer improve 10% & 15% on ImageNet-C
1/4
If you stop reading the literature here, the flat-minima story looks vindicated: the Hessian definition was broken but the phenomenon is real, and SAM is the tool that makes it actionable. Then Kaddour et al. [7] looked at what happens as the model and the data both grow. The SAM advantage shrinks and then essentially disappears, and at the scale where generalization matters most flat-minima optimization and plain Adam converge to the same test loss.
So the picture we are left with is uncomfortable. Sharpness in the naive Hessian sense is not causal for generalization. A reparameterization-invariant notion of sharpness correlates with generalization at small and medium scale, and optimizers that target it produce real and replicable gains on architectures with weaker priors. At very large scale, the correlation weakens and the SAM advantage fades, and the deeper reason is unclear. My guess, and I could be wrong about this, is that at scale the data distribution and the trajectory of the optimizer dominate whatever geometric property the final minimum has, and the landscape framing stops being the right framing. But the guess is unfalsifiable in any useful sense, so it is more of an intuition than a reading.
The argument will not die because both sides have strong evidence in the regimes they care about, and the regimes disagree.
References
- [1] S. Hochreiter and J. Schmidhuber. Flat minima. Neural Computation, 9(1):1–42, 1997.
- [2] N. S. Keskar, D. Mudigere, J. Nocedal, M. Smelyanskiy, and P. T. P. Tang. On large-batch training for deep learning: Generalization gap and sharp minima. arxiv 1609.04836, 2016.
- [3] L. Dinh, R. Pascanu, S. Bengio, and Y. Bengio. Sharp minima can generalize for deep nets. arxiv 1703.04933, 2017.
- [4] G. K. Dziugaite and D. M. Roy. Computing nonvacuous generalization bounds for deep (stochastic) neural networks with many more parameters than training data. arxiv 1703.11008, 2017.
- [5] P. Foret, A. Kleiner, H. Mobahi, and B. Neyshabur. Sharpness-aware minimization for efficiently improving generalization. arxiv 2010.01412, 2020.
- [6] X. Chen, C.-J. Hsieh, and B. Gong. When vision transformers outperform ResNets without pre-training or strong data augmentations. arxiv 2106.01548, 2021.
- [7] J. Kaddour, L. Kamalaruban, A. Weller, and M. J. Robbiani. When do flat minima optimizers work? arxiv 2202.00661, 2022.