Grokking, a puzzle and four explanations that might be the same thing
In January 2022, OpenAI published a short paper that describes a training curve unlike anything else in deep learning. A small transformer is trained on modular arithmetic until it memorizes the training set, with training loss dropping essentially to zero while validation accuracy sits at chance. Nothing further happens for many more steps. Then, after what looks like a ridiculous delay, validation accuracy jumps from chance to a hundred percent in a narrow window of training steps. The network has generalized, but long after it already fit the data.
The paper is Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets by Power et al. [1]. I came across it maybe a week after it was posted and did not really know what to do with it for a while.
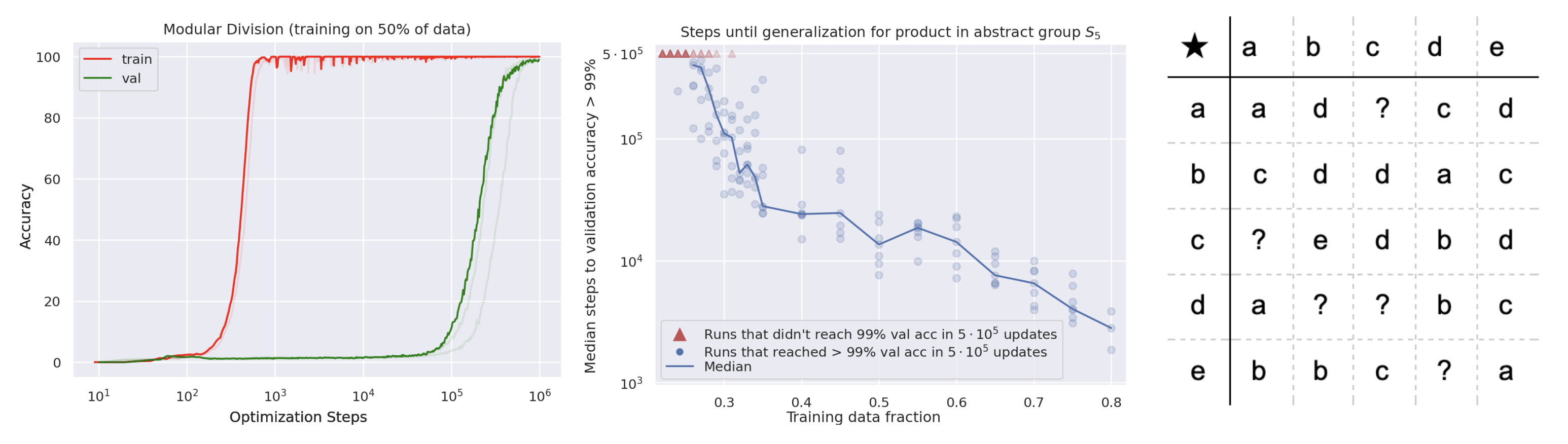
Why this is a puzzle
Standard stories about generalization do not predict a long delay. The VC and Rademacher bound based stories say generalization either happens or does not, as a function of how well the hypothesis class matches the data distribution. The implicit bias stories say SGD finds a flat minimum that generalizes, but that minimum should be found at roughly the same time the training loss converges, not a thousand steps later. Grokking says the loss landscape has a second stage that is not driven by training loss. Something else is driving the weights during the period where training loss is already zero.
Four explanations
The first explanation, and the one the original paper already gestures at, is that weight decay is a slow regularizer. The paper observes that grokking only happens with weight decay turned on. Once training loss is zero, the weight decay term keeps pulling the norm of the weights down even though the loss gradient is tiny. This is a slow drift toward a lower-norm solution, which may be the solution that generalizes.
The second explanation comes from mechanistic interpretability. Neel Nanda and collaborators [2] identified specific circuits inside the small grokking networks that implement modular arithmetic via Fourier decomposition. The grokking transition is the point at which these circuits finish assembling. Before the transition the network memorizes via a brute-force lookup; afterward, it actually computes. The circuits-level framing that this line of work builds on is laid out in Elhage et al. [3], which is where I would send someone who wants to understand what it means to talk about circuits inside a transformer at all.
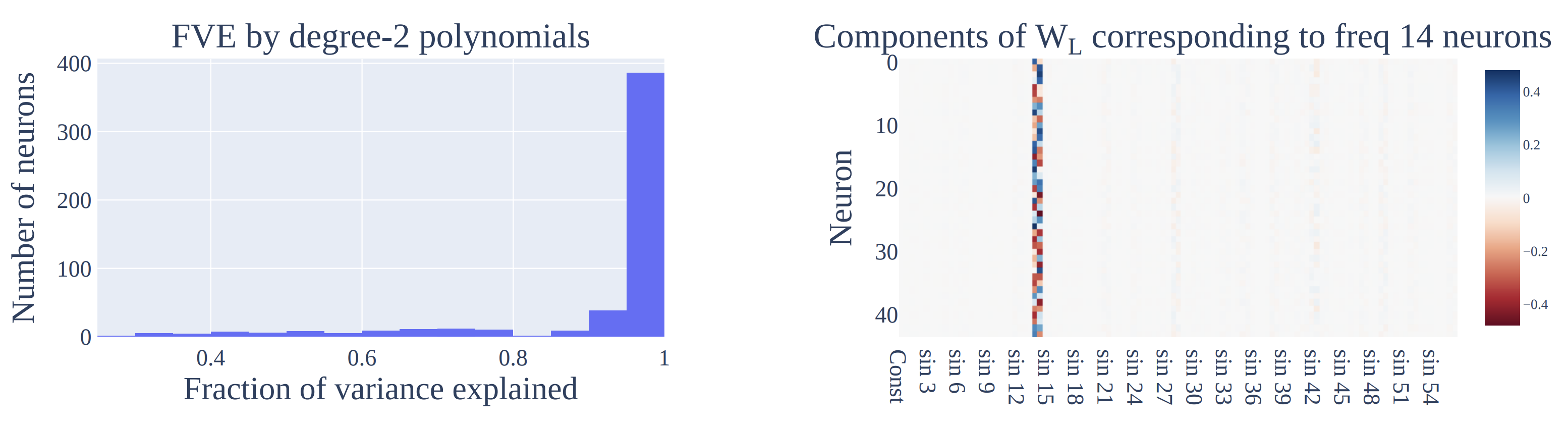
The third explanation is the same thing dressed in the language of optimization. Gradient descent with L2 regularization on an overparameterized model has two forces pushing on the weights, the loss gradient that wants to fit the data and the decay that wants to shrink the norm. Once the data is interpolated, the loss gradient near zero essentially vanishes in the directions that matter, and the decay takes over. This selects the minimum-norm solution among all interpolants. For modular arithmetic, the minimum-norm interpolant happens to be the Fourier one.
The fourth explanation is that grokking and double descent are the same phenomenon observed at different resolutions. In both [6, 7], the network first memorizes, then finds a lower-complexity solution, and the transition happens as a function of either model size, data size, or training time. Grokking is double descent over time. Whether this framing holds up beyond the lab is a separate question. By 2020 people were already asking whether double descent, observed reliably in CIFAR with label noise, also shows up in large language models as they scale. The exchange below, Preetum Nakkiran replying to Greg Yang in June 2020, is a good snapshot of that disagreement. (It is not a tweet about grokking directly, but the question is right next door.)
This is not true (Figure 4a). See also this recent paper [arxiv 2002.11328] where they uncover underlying double-descent in variance even when it does not appear in test error.
— Preetum Nakkiran (@PreetumNakkiran) June 26, 2020
Read together, these four explanations look less like alternatives than like one story told at different levels of abstraction. Weight decay does it, and the mechanism by which it does it is the selection of the minimum-norm interpolant, and that interpolant happens to be the Fourier circuit because Fourier is the low-rank structure of modular arithmetic, and the general shape of this, a fast memorization followed by a slow compression, is the same shape double descent has when it is resolved over time rather than over model size. Under this reading, grokking is not a mysterious new phenomenon. It is the cleanest visualization we have of the implicit regularization thesis, because the task has a single low-rank solution that the network is eventually going to find.
What I still cannot account for, and what none of the explanations above quite nails, is the sharpness of the transition itself. If the norm is being pulled down continuously and the circuits are being assembled continuously, you would expect validation accuracy to rise smoothly. It does not, it snaps. My current guess is that the sharpness is an artifact of the softmax classifier, which translates gradual changes in logits into a step change in the top-1 prediction only once a threshold is crossed, but I have not seen this worked out carefully.
References
- [1] A. Power, Y. Burda, H. Edwards, I. Babuschkin, and V. Gross. Grokking: Generalization beyond overfitting on small algorithmic datasets. arxiv 2201.02177, 2022.
- [2] N. Nanda, L. Chan, T. Lieberum, J. Smith, and J. Steinhardt. Progress measures for grokking via mechanistic interpretability. arxiv 2301.05217, 2023.
- [3] N. Elhage et al. A mathematical framework for transformer circuits. transformer-circuits.pub/2021/framework, 2021.
- [4] Z. Liu, E. Michaud, and M. Tegmark. Omnigrok: Grokking beyond algorithmic data. arxiv 2210.01117, 2022.
- [5] V. Thilak, E. Littwin, S. Zhai, O. Saremi, R. Paiss, and J. Susskind. The slingshot mechanism: An empirical study of adaptive optimizers and the grokking phenomenon. arxiv 2206.04817, 2022.
- [6] M. Belkin, D. Hsu, S. Ma, and S. Mandal. Reconciling modern machine learning practice and the bias-variance trade-off. arxiv 1812.11118, 2018.
- [7] P. Nakkiran, G. Kaplun, Y. Bansal, T. Yang, B. Barak, and I. Sutskever. Deep double descent: Where bigger models and more data hurt. arxiv 1912.02292, 2019.