The lottery ticket hypothesis, what it claimed and what survived the replication
The cleaner statement is not that winning tickets exist at initialization. It is that once a training run has committed to a basin, there is a sparse subnetwork in that basin that matches the dense one.
Key terms used in this post
- iterative magnitude pruning
- training to convergence, removing the smallest-weight connections, rewinding, retraining, repeat.
- rewinding
- resetting the surviving weights to their values at a specific earlier step before retraining.
- mode connectivity
- the fact that two neural-network minima can often be connected by a low-loss linear path in weight space.
The lottery ticket hypothesis was proposed by Frankle and Carbin in early 2019 [1]. The claim, stripped to its sharpest form, is that a randomly initialized neural network contains small subnetworks whose weights at that initial point already encode a trainable solution. Train the full network, prune the smallest-magnitude weights, rewind the remaining weights to their values at initialization, train from there, and we match the full network’s accuracy with a fraction of the parameters. The pruned connections never had to exist. A “winning ticket” was drawn at initialization.
This would be a surprising statement about how deep networks represent functions. If true, it means the optimization process is not building up structure from nothing; it is finding a subnetwork whose random init was already right, and then decorating the rest of the parameters in ways that do not matter. The pruning literature had long suspected something like this, but nobody had pinned down an operational procedure that reliably produced trainable sparse networks at a comparable accuracy.
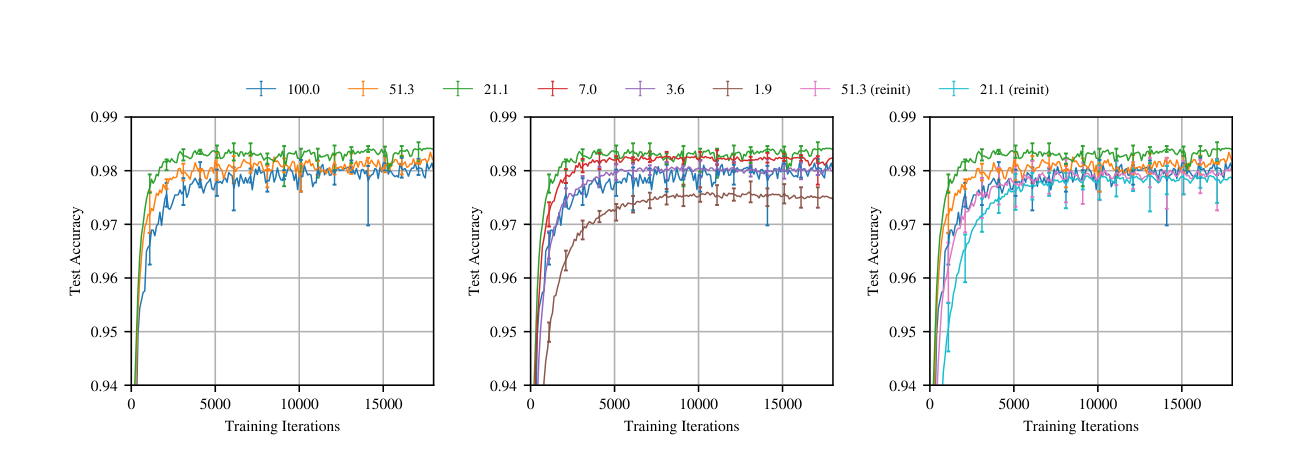
What Frankle and Carbin actually did
The procedure, iterative magnitude pruning with rewinding, is mechanical and worth writing out. Train the full network to convergence. Set the smallest-magnitude p percent of weights to zero and freeze them. Rewind the remaining weights to their initial values before training, not to the post-training values. Retrain from there. Repeat for several rounds, pruning a little at a time, until we have removed as many weights as we can while still matching accuracy. The subnetwork produced at the end is the winning ticket for this initialization and this data.
The results on MNIST and small CIFAR networks are clean. Sparsity down to a few percent of the original weights without loss of accuracy. The tickets do not transfer; a winning ticket found on one initialization does not train on another initialization. The structure has to have been in the original random draw.
The Liu rebuttal
Liu et al. [2] wrote a paper titled “Rethinking the Value of Network Pruning” that reran the Frankle procedure on larger networks and datasets and reported a very different conclusion. For their setting, the winning ticket initialization was no better than a fresh random initialization of the same sparse topology, as long as we trained long enough. In other words, the claim that the initial weights were special broke down. What mattered was the sparse connectivity pattern, not the specific initialization values.
Read in isolation, this looks like a straightforward refutation. Read together with the original paper, it is a regime boundary. Frankle and Carbin’s strongest claims held for small MNIST and CIFAR-10 networks. Liu and coauthors were running on ImageNet-scale networks where those claims no longer held. Something breaks when we scale up the model, and it took a year to figure out what.
The rewinding fix
Frankle himself wrote the follow-up that fixed the scaling issue [3]. Instead of rewinding the surviving weights to their values at initialization, rewind them to their values at a small number of training steps into the run. A few hundred SGD steps for ImageNet-scale networks, rather than zero. With this change, the lottery ticket procedure works on ImageNet, and the trained sparse subnetwork matches the dense baseline at high sparsity.
This is a softer version of the original hypothesis. It is not that random initialization contains a winning ticket. It is that a very short period of training is enough to pick out a winning ticket. The first few hundred steps lock in something about the geometry of the loss landscape, and after that point the sparse subnetwork is determined. If we rewind past that point, we lose it.
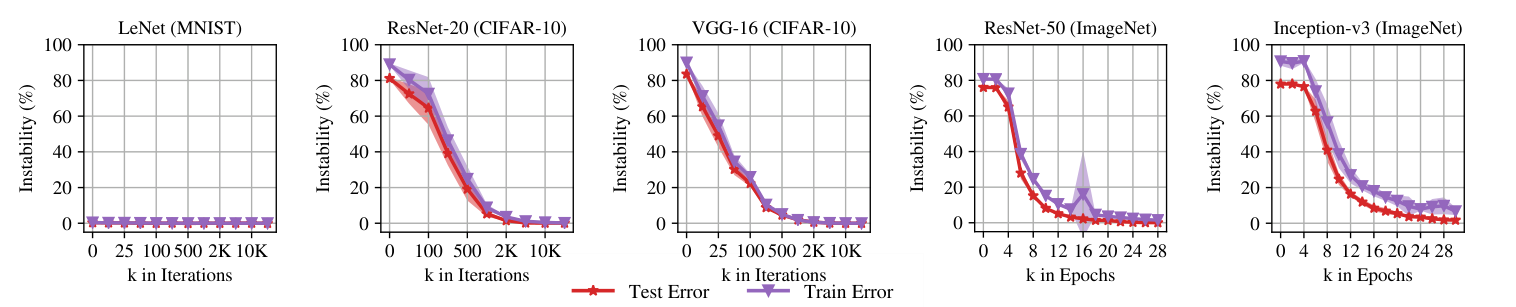
Why rewinding works
The explanation that has held up comes from Frankle’s companion paper on linear mode connectivity [4]. At initialization, two training runs starting from the same weights but different data orders end up in different loss-landscape basins; the linear interpolation between their final weights passes through a region of high loss. After a few hundred steps, the two runs end up in the same basin; the linear interpolation between them stays low-loss throughout. The moment at which basin membership becomes determined is the rewinding point.
A winning ticket lives inside a basin. If we rewind past the point where basin membership is determined, the sparse subnetwork has no basin to live in and training diverges. If we rewind to exactly the point of basin determination, or any point after it, the subnetwork has a consistent landscape and trains successfully. The magic of the original paper was that for small MNIST and CIFAR networks, the basin is determined essentially at initialization, so late rewinding and init-rewinding give the same answer. For larger networks this breaks, and we need to stay inside the basin.
What survives
The cleaner way to state the result after all this is not “winning tickets exist at initialization.” It is “once a training run has committed to a basin, there is a sparse subnetwork in that basin that matches the dense one.” The strong form about initialization does not survive at scale. The weaker form about basins survives everywhere it has been tested. This is a real statement about deep networks and it is in the same family as mode connectivity, the linear paths that connect seemingly different minima [4, 6], and eventually permutation-based weight alignment [7].
Davis Blalock’s 2020 MLSys retrospective on the pruning literature is the single best summary of what survived across the Frankle-to-Liu transition; he untangles which pruning results are real and which are artifacts of reporting protocols. The strong-versus-weak lottery ticket distinction he uses there is the right vocabulary for this debate, and the framing of late rewinding as “checkpoint pruning” is closer to what the procedure actually is than the original lottery metaphor.
What I think the literature has not properly absorbed is that the interesting result for theory is the rewinding point itself. If we can identify the moment at which basin membership gets locked in, we have identified something structural about the loss landscape that standard theory does not currently explain. Lewkowycz’s catapult phase [5] and the edge-of-stability literature are pointing at similar territory from different angles. There should be a unified picture here, and the lottery ticket framing is one of the cleanest entry points into it.
References
- [1] J. Frankle and M. Carbin. The lottery ticket hypothesis: Finding sparse, trainable neural networks. arxiv 1803.03635, 2018.
- [2] Z. Liu, M. Sun, T. Zhou, G. Huang, and T. Darrell. Rethinking the value of network pruning. arxiv 1810.05270, 2018.
- [3] A. Renda, J. Frankle, and M. Carbin. Comparing rewinding and fine-tuning in neural network pruning. arxiv 2003.02389, 2020.
- [4] J. Frankle, G. K. Dziugaite, D. M. Roy, and M. Carbin. Linear mode connectivity and the lottery ticket hypothesis. arxiv 1912.05671, 2019.
- [5] A. Lewkowycz, Y. Bahri, E. Dyer, J. Sohl-Dickstein, and G. Gur-Ari. The large learning rate phase of deep learning: The catapult mechanism. arxiv 2003.02218, 2020.
- [6] T. Garipov, P. Izmailov, D. Podoprikhin, D. Vetrov, and A. G. Wilson. Loss surfaces, mode connectivity, and fast ensembling of DNNs. arxiv 1802.10026, 2018.
- [7] S. K. Ainsworth, J. Hayase, and S. Srinivasa. Git re-basin: Merging models modulo permutation symmetries. arxiv 2209.04836, 2022.